Part 3 The Means and Effects Models
3.1 ANOVA Bookkeeping
In Part 1 we mentioned ANOVA is a way to keep track of the variation in a response variable. Figure 3.1 provides a schematic for how we can think about this for our InsectSprays data set example introduced in Part 2.

Figure 3.1: Conceptual diagram for variation accounting in the insecticide example.
In 1-way ANOVA we partition the total variation in our response variable (SS Total) into two parts- variation due to treatment (SS Treatment) and the random error left over (SS Error), viz (Kutner et al. 2005).,
\[SS_{total} = SS_{trt} + SS_{error} = \sum_{i,j} (y_{ij} - \overline{y}_{..})^2\] \[ SS_{trt} = \sum_{i,j} (\overline{y}_{i.} - \overline{y}_{..})^2 \] \[ SS_{error} = \sum_{i,j} (y_{ij} - \overline{y}_{i.})^2 \]
Don’t be intimidated by the formulas above. Basically, all we are saying is that we can decompose the total deviation from the overall mean response into two components:
- The deviation of each treatment group mean from the grand mean of the response variable (between treatment group mean variation)
- The deviation of each observation from its treatment group mean (within treatment group variation)
Figures 3.2, 3.3, and 3.4 provide visuals for each variation component in the context of our InsectSprays example.
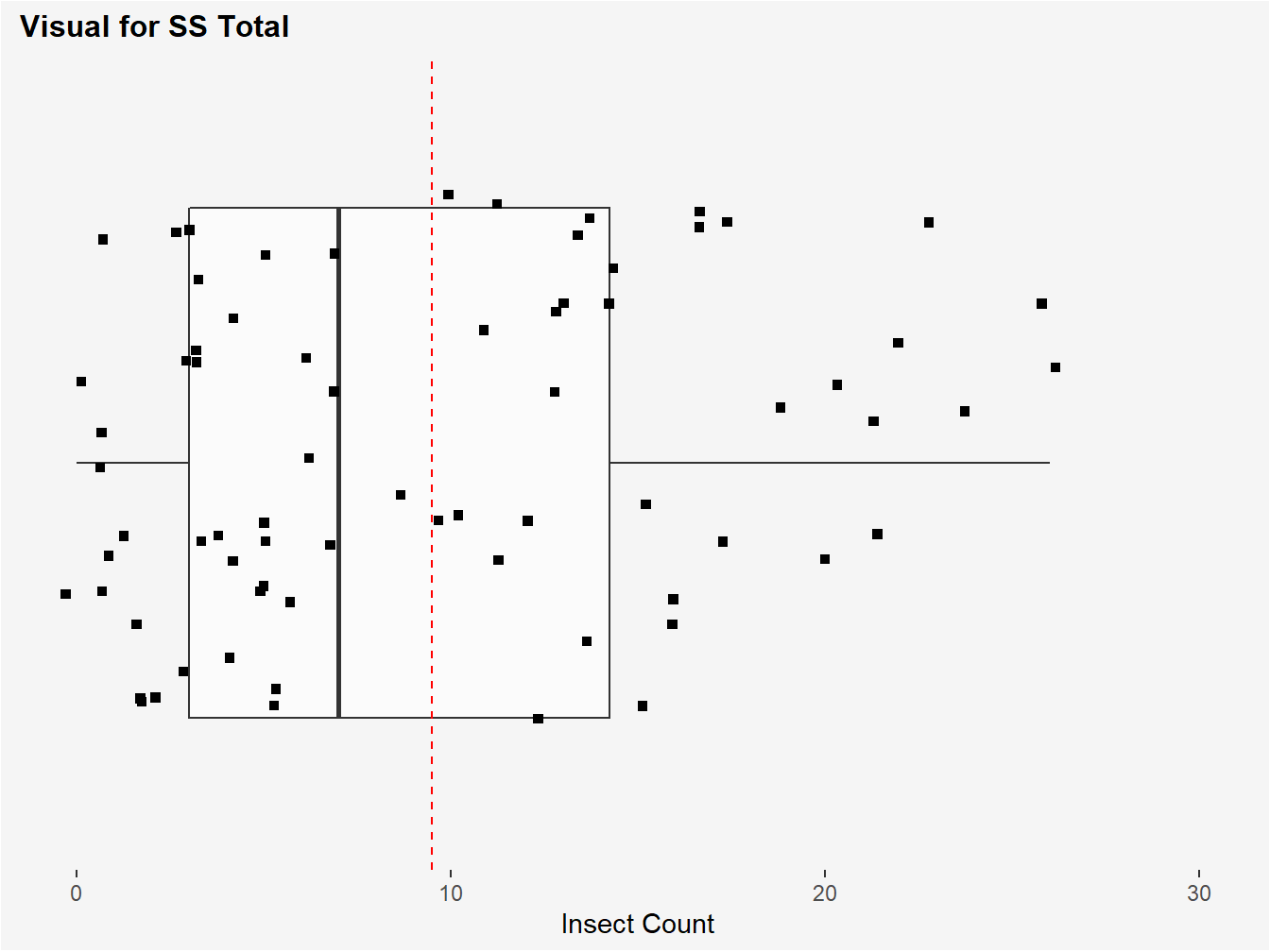
Figure 3.2: Visual of SS Total. The red-dotted line represents the grand mean insect count calculated from all insect plots. SS total is computed by subtracting each observed count from a plot from this grand mean, squaring, and then summing these values.
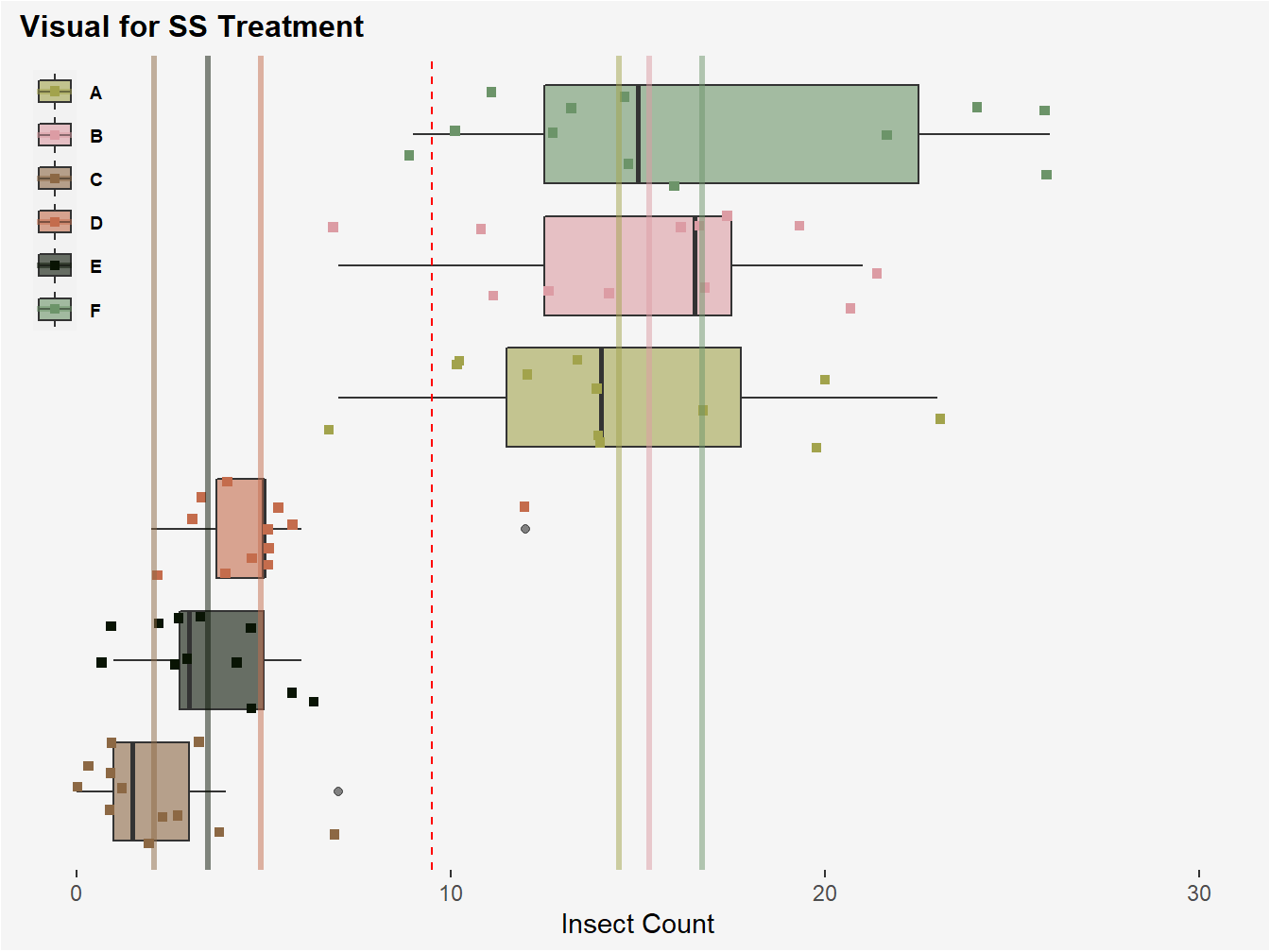
Figure 3.3: Visual of SS Treatment. The red-dotted line once again represents the grand mean for insect count. SS Treatment is computed by subtracting each treatment group mean for insect count (color coded lines) from this grand mean, squaring, and then multiplying by the j replicates comprising each treatment group, in this case 12. The 6 values corresponding to each treatment group resulting from this computation are then summed.
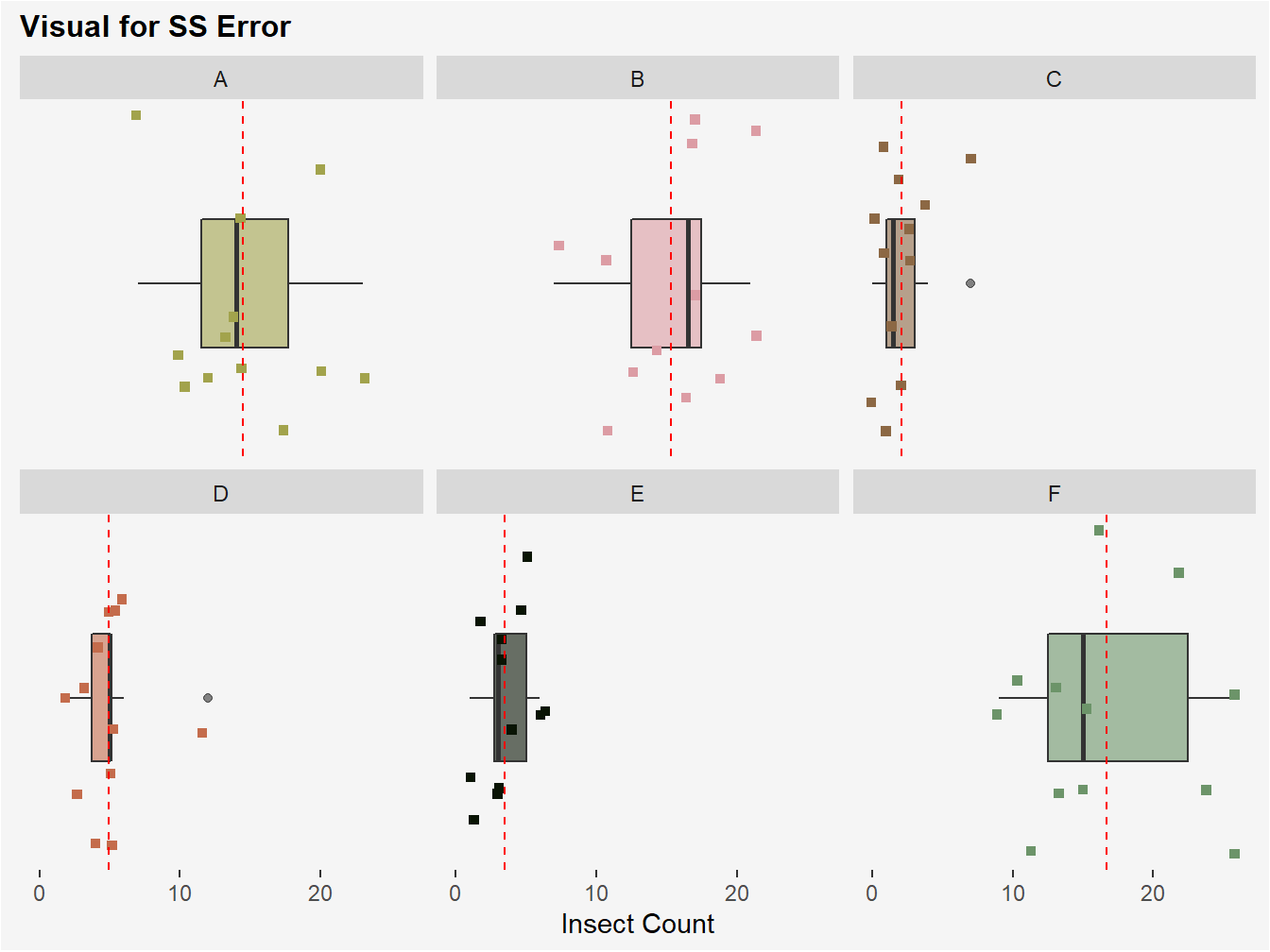
Figure 3.4: Visual of SS Error. The red-dotted line in each panel represents each treatment group mean for insect count. SS Error is computed by subtracting each observed count from a plot from its respective treatment group mean, squaring, and then summing these values.
ANOVA compares the variability due to the treatment to that due to error to generate a test statistic. We will now see how we can compute these variance quantities and do ANOVA in R by applying a model to our data.
3.2 Means Model
We can model our 1-way ANOVA data using the means model, an additive linear model for when our explanatory variable is categorical, viz.,
\[y_{ij} = \mu_{i} + \epsilon_{ij} \]
where \(y_{ij}\) ~ independent and Normal (\(\mu_{i}, \sigma^2\)) and \(\epsilon_{ij}\) ~ independent and Normal (\(0, \sigma^2\)). Let’s define what the parameters in this expression represent in the context of our InsectSprays example:
\(y_{ij}\) represents the insect count for the \(jth\) insect plot given the \(ith\) insecticide spray
\(\mu_{i}\) represents the true mean insect count for all insect plots given the \(ith\) insecticide spray
\(\epsilon_{ij}\) represents the error for the for the \(jth\) insect plot given the \(ith\) insecticide spray
Note that the equation form of this model uses parameter notation (e.g. we are talking about a population). When we use this model in practice we estimate the parameters with statistics from our data. Without further ado, let’s do some computing!
3.2.1 Employing the Means Model to do 1-way ANOVA in R
The below code uses the means model and matrix algebra to eventually compute the ANOVA F-statistic for our InsectSprays example.
### ANOVA Preliminaries
## Data
insects <- InsectSprays
## response variable (n x 1 matrix)
response_variable <- insects %>%
pull(count) %>%
as.matrix()
## Design matrix (n x p matrix)
# Each column is using indicator coding, a ‘1’ for the treatment, and 0 for other. So column 1 will generate the mean for treatment level1, column 2 for treatment level2, and column 3 for treatment level3 and so on.
design_matrix <- model.matrix(~ insects$spray + 0)
## p x 1 matrix of treatment means
trt_means <- solve(crossprod(design_matrix), crossprod(design_matrix, response_variable))
### ANOVA
n <- nrow(response_variable)
p <- ncol(design_matrix)
j <- matrix(1, n, n)
## Variation computations
ss_tot <- crossprod(response_variable) - (1/n) * crossprod(response_variable, j) %*% response_variable
ss_trt <- (t(trt_means) %*% crossprod(design_matrix, response_variable)) - (1/n) * crossprod(response_variable, j) %*% response_variable
ss_error <- ss_tot - ss_trt
## Degrees of freedom
total_df <- n - 1
trt_df <- p - 1
error_df <- n - p
## Compute F-stat
MS_trt <- ss_trt / trt_df
MS_error <- ss_error / error_df
F_stat <- MS_trt / MS_errorA few points to note about the code above:
- The design matrix (often denoted X) is useful to estimate our \(\mu_{i}\) parameters (treatment means) from the means model. The design matrix is a way to represent the number of treatment groups and replicates per treatment group. Our
InsectSpraysdata is a little lengthy to show its full means model design matrix, so let’s simplify and say we only have only 6 insect plots with 3 different sprays (2 replicates per spray). We represent the design matrix (X) and compute the treatment means (\(\overline{y}_{i.}\)), viz.,
\[\left[\begin{array} {rrr} y_{1,1} \\ y_{1,2} \\ y_{2,1} \\ y_{2,2}\\ y_{3,1} \\ y_{3,2} \\ \end{array}\right] = \left[\begin{array} {rrr} 1 & 0 & 0 \\ 1 & 0 & 0\\ 0 & 1 & 0\\ 0 & 1 & 0\\ 0 & 0 & 1\\ 0 & 0 & 1\\ \end{array}\right] \left[\begin{array} {rrr} \mu_{1} \\ \mu_{2} \\ \mu_{3} \\ \end{array}\right] + \left[\begin{array} {rrr} \epsilon_{1,1} \\ \epsilon_{1,2} \\ \epsilon_{2,1} \\ \epsilon_{2,2}\\ \epsilon_{3,1} \\ \epsilon_{3,2} \\ \end{array}\right]\] \[\overline{y}_{i.} = (X'X)^{-1}X'Y\]
- Our SS values are computed using matrix operations carrying out the equations described in 3.1. For brevity I will not describe the operations in detail.
- Lastly, our ANOVA F-statistic is calculated by taking the ratio of our mean sum of squares treatment (between treatment group variation) and mean sum of squares error (within treatment group variation). A high F-statistic is our measure to suggest the variation is largely explained by our explanatory variable rather than random variation. In the context of the means model, it allows us to conclude that at least one of our treatment means is significantly different from 0. The value of our F-statistic for our
InsectSpraysexample computed above is:
## [,1]
## [1,] 34.70228This is the same result as using R’s built in anova function
## Analysis of Variance Table
##
## Response: insects$count
## Df Sum Sq Mean Sq F value Pr(>F)
## insects$spray 5 2668.8 533.77 34.702 < 2.2e-16 ***
## Residuals 66 1015.2 15.38
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 13.3 Effects Model
We can model our 1-way ANOVA data using another additive linear model for when our explanatory variable is categorical, called the effects model, viz.,
\[y_{ij} = \mu + \tau_{i} + \epsilon_{ij} \]
where \(y_{ij}\) ~ independent and Normal (\(\mu + \tau_{i}, \sigma^2\)) and \(\epsilon_{ij}\) ~ independent and Normal (\(0, \sigma^2\)). Similar to what we did with the means model, lets define what the parameters of the effects model represent in the context of our InsectSprays example:
\(y_{ij}\) represents the insect count for the \(jth\) insect plot given the \(ith\) insecticide spray
\(\mu\) represents the true mean insect count for all insect plots given a spray
\(\tau_{i}\) represents the effect of the the \(ith\) insecticide spray on insect count
\(\epsilon_{ij}\) represents the error for the for the \(jth\) insect plot given the \(ith\) insecticide spray
An effect in the context of this model is the difference between the mean for the \(ith\) treatment and the grand mean. We operate under the constraint that all our estimated effects sum to 0, viz.,
\[\sum\tau_{i} = 0\] You will see the role of this assumption after we employ the effects model in R.
3.3.1 Employing the Effects Model to do 1-way ANOVA in R
### ANOVA Preliminaries
## Data
insects <- InsectSprays
## response variable (n x 1 matrix)
response_variable <- insects %>%
pull(count) %>%
as.matrix()
## Design matrix (n x p matrix)
# First column is now an intercept term used to compute the grand mean
contrasts(insects$spray) <- contr.sum(6, contrasts=TRUE)
design_matrix <- model.matrix(~ insects$spray)
## p x 1 matrix of effects model parameters
model_param <- solve(crossprod(design_matrix), crossprod(design_matrix, response_variable))
### ANOVA
n <- nrow(response_variable)
p <- ncol(design_matrix)
j <- matrix(1, n, n)
## Variation computations
ss_tot <- crossprod(response_variable) - (1/n) * crossprod(response_variable, j) %*% response_variable
ss_trt <- (t(model_param) %*% crossprod(design_matrix, response_variable)) - (1/n) * crossprod(response_variable, j) %*% response_variable
ss_error <- ss_tot - ss_trt
## Degrees of freedom
total_df <- n - 1
trt_df <- p - 1
error_df <- n - p
## Compute F-stat
MS_trt <- ss_trt / trt_df
MS_error <- ss_error / error_df
F_stat <- MS_trt / MS_errorOur ANOVA computation is largely the same as what we did for the means model, but our design matrix this time around helps compute the parameters for the effects model, namely our grand mean and effects for our treatments.
## [,1]
## (Intercept) 9.500000
## insects$spray1 5.000000
## insects$spray2 5.833333
## insects$spray3 -7.416667
## insects$spray4 -4.583333
## insects$spray5 -6.000000The intercept term here is our grand mean insect count- 9.5 insects. Using our effect estimations we can easily calculate means for the treatment groups:
model_param %>%
as.data.frame() %>%
rename(param = V1) %>%
tibble::rownames_to_column() %>%
mutate(trt_mean = 9.5 + param)## rowname param trt_mean
## 1 (Intercept) 9.500000 19.000000
## 2 insects$spray1 5.000000 14.500000
## 3 insects$spray2 5.833333 15.333333
## 4 insects$spray3 -7.416667 2.083333
## 5 insects$spray4 -4.583333 4.916667
## 6 insects$spray5 -6.000000 3.500000Notice that we are missing one effect estimate for spray F! This is because we must drop a treatment group from the model for the matrix operations to work (we sacrifice a treatment group effect to compute the grand mean). We can find the missing effect by recalling the model assumption \(\sum\tau_{i} = 0\).
missing_effect <- model_param %>%
as.data.frame() %>%
rename(param = V1) %>%
tibble::rownames_to_column() %>%
slice(2:6)
sum(missing_effect$param)## [1] -7.166667Our missing effect for spray F is therefore 7.167 insects.
Our F-statistic remains the same as what it was for the means model when computing with the effects model. It is again 34.7. The interpretation changes from what we said in the means model- it suggests that at least one of the effects of the \(ith\) insect spray on insect count are not equal to 0.
3.4 Check-in
- Suppose we ran our
InsectSpraysexperiment twice using only sprays D, E, and F and obtained the following results:
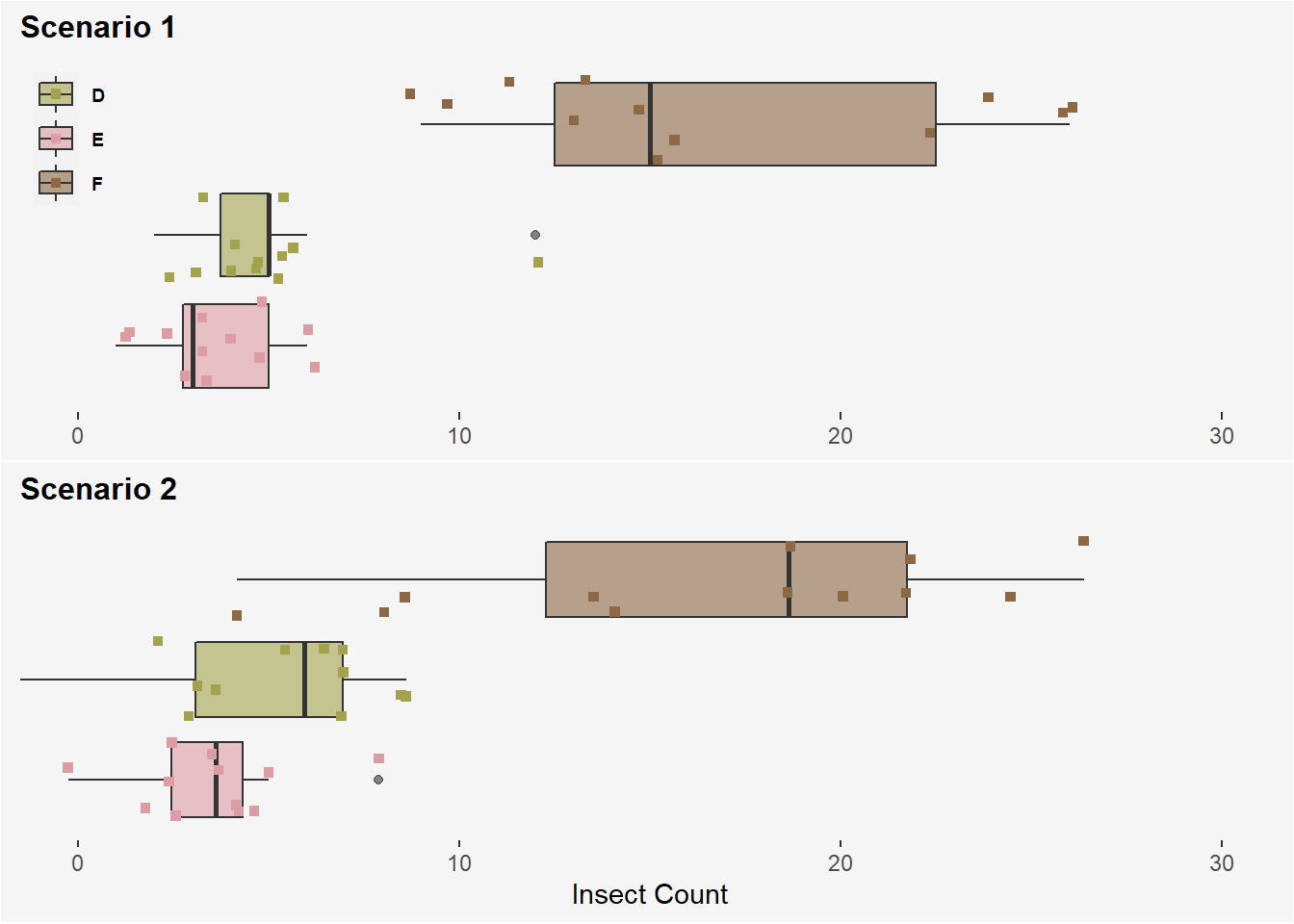
Scenario 1
## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 3
## spray mean `std dev`
## <fct> <dbl> <dbl>
## 1 D 4.92 2.50
## 2 E 3.5 1.73
## 3 F 16.7 6.21Scenario 2
## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 3
## spray mean `std dev`
## <fct> <dbl> <dbl>
## 1 D 4.92 3.2
## 2 E 3.5 2
## 3 F 16.7 7.Assume in both scenarios that 12 replicates per treatment group were used. Will one of the two data sets produce a larger F-statistic (Scenario 1 or Scenario 2)? Why or why not.
- Suppose we want to run an ANOVA on a experiment set-up with 3 different treatment groups (2 replicates per treatment) using the effects model. There is 1 observation of the response variable per replicate for this experiment. To compute our model parameters, how would we set up the design matrix?
References
Kutner, Michael H, Christopher J Nachtsheim, John Neter, William Li, and others. 2005. Applied Linear Statistical Models. Vol. 5. McGraw-Hill Irwin New York.